




I’d like to start with a bit of context on who we are and what we do. I work for the CNP API team which is a crucial part of the Core News Product organization. CNP is a modern multi-tenant publishing platform used by almost all brands within the Schibsted News Media. It provides hundreds of Schibsted journalists with digital tools to create and manage news content that reaches most of the Scandinavian population.
Last year, we were tasked with creating a new service that would allow journalists to send push notifications. Mostly to inform end-users about breaking news or updates on topics they are interested in. The plan was to replace a string of brand custom push solutions with one centralized service that all the Schibsted brands can share. Purpose? To cut the cost that comes with operating many solutions doing the same thing, to improve the performance and reliability of the service, and to increase future potential by being able to deliver new features to all the service clients.
The following list shows some of the functional requirements we had:
- journalists trigger the push notifications from within the Content Management System (CMS)
- end-users subscribe to topics they are interested in (eg. sport, news, politics)
- service supports push to more than one topic eg. “push to all users that subscribe to sports or news”, without duplication
- service complies with all the data protection and privacy rules (also known as GDPR)
But, what we are interested in mostly here are the technical requirements, and those were pretty straightforward:
- deliver 5 million push notifications in 10 seconds
In this blog post, I describe how we thought about the problem, how the system evolved, what challenges we faced and how we solved them. Here is our story of building a Push service.
Parallel processing with AWS Lambda
From the beginning, we felt that in order to meet the technical requirements we might need a massive parallelization. We wanted to start simple. The first idea was to have a backend service that is responsible for keeping track of all recipients and what kind of pushes should they receive. We called this relation “subscription”. The same backend service would be responsible for the delivery of the push messages. Here is the execution flow:
- A journalist orders a push notification.
- The backend service queries its storage to get all the matching recipients.
- The backend service batch the recipients and uses a topic (AWS SNS) to fan out the batches to serverless functions (AWS Lambda) relying on lambda function scaling.
- The AWS Lambda sends pushes to Apple/Google APIs (APNs/FCM) with high concurrency.
The following diagram shows the idea:

We mocked some of the dependencies (APNs/FCM) and we did performance tests. All went well and this was indeed a promising path until we stumbled upon this recommendation from Apple:
Keep your connections with APNs open across multiple notifications; do not repeatedly open and close connections. APNs treats rapid connection and disconnection as a denial-of-service attack. You should leave a connection open unless you know it will be idle for an extended period of time—for example, if you only send notifications to your users once a day, it is acceptable practice to use a new connection each day.
This basically ruled out going with lambdas.
Parallel processing with worker processes
The idea is pretty much similar to the one with AWS Lambda, but in this case, the worker processes (let’s call them senders) were responsible for the execution of push requests to the APNs/FCM. The worker is a process that runs in an infinite loop polling and processing jobs from a queue (AWS SQS). Each of the workers maintains a long-lived connection with APNs and FCM that it uses to shoot push messages as fast as possible, in a fire and forget fashion.
Let’s start with an architecture diagram and then go a bit more into details on how we structured data and designed the interactions between services and processes.

Here is the description of the crucial components and processes from the diagram above:
CMS – content management system. Interface for journalists to create articles and order push notifications to end-users on selected topics.
Push Service – backend service that encapsulates everything it takes to deliver push notifications to the end-users. It’s composed of 3 main processes kept in a single repository and deployed together:
- Subscription API – web process. Exposes an REST API for mobile devices to send end-user subscriptions.
- Push API – web process. Exposes an REST API for the CMS to order push notifications.
- Sender – worker process. Responsible for finding matching subscriptions for the ordered push and then sending notifications to the end-user devices using Apple/Google APIs.
In the diagram above we have two crucial flows. Let’s describe them in more detail:
Subscriptions handling
End-user has a news app installed on a mobile device. The app periodically sends subscription requests to the subscription API expressing user’s interest in particular topics.
We decided to partition user subscriptions randomly into 240 shards. In AWS Aurora we stored all the subscriptions. We’ve deployed 8 sender processes into 8 fat EC2 instances (c5.xlarge(1)) in a way that each process occupies a single EC2 alone. This was in order to make sure that every process has exclusive access to the instance CPU and memory. We had configured each sender to own a unique range of subscription shards. On bootstrap, each of the 8 senders would read from the permanent storage into its in-memory cache 30 shards (total 240 shards / 8 senders = 30 shards).
So, eg. given 5 million subscriptions split into 240 shards means that each shard contains roughly 21,000 subscriptions. In such case, every sender keeps in its cache 30 shards and that’s gonna be 630,000 subscriptions.
Then each sender would subscribe to a Redis Pub/Sub to receive notifications from the subscription API process about new subscriptions and thus keep its in-memory cache in sync.
(1) – our benchmarks showed that c5.xlarge has both enough RAM to store 30 shards of subscriptions in the in-memory cache and CPU to send push messages out fast enough.
Push delivery
When a CMS user (a journalist) decides to send a push notification the CMS service would post a message to the push API. Then the push API uses a topic (AWS SNS) to fan out the message to 8 queues (AWS SQS). Every sender process picks up the message from its dedicated queue and executes a query (we used cqengine here) against its limited view of the world (30 in-memory shards). Next, it sends out the push message for all the matched subscriptions as fast as possible.
In the process, we’ve found out that when we’re talking to Apple/Google APIs in fact we are hitting servers in California. So, although we operate in Europe (AWS eu-west-1 region) we decided to place the Push Service (subscription API, push API, and senders) in California (AWS us-west-1region) to be closer to those APIs. This was a major performance improvement, especially when it comes to the speed of pushing out the notifications.
Optimization – split the Push service
At some point, we noticed that the push API is a bit sluggish. This was because in Europe we had both our users and other services while the Push service itself was in the US. It turned out that when sending a Push request we were crossing the Atlantic ocean more times than we really need to, sometimes via the public internet. This was also a problem for the mobile apps that do not handle timeouts very well.
The following diagram shows how it looked (subscription flow in yellow, push delivery flow in green):
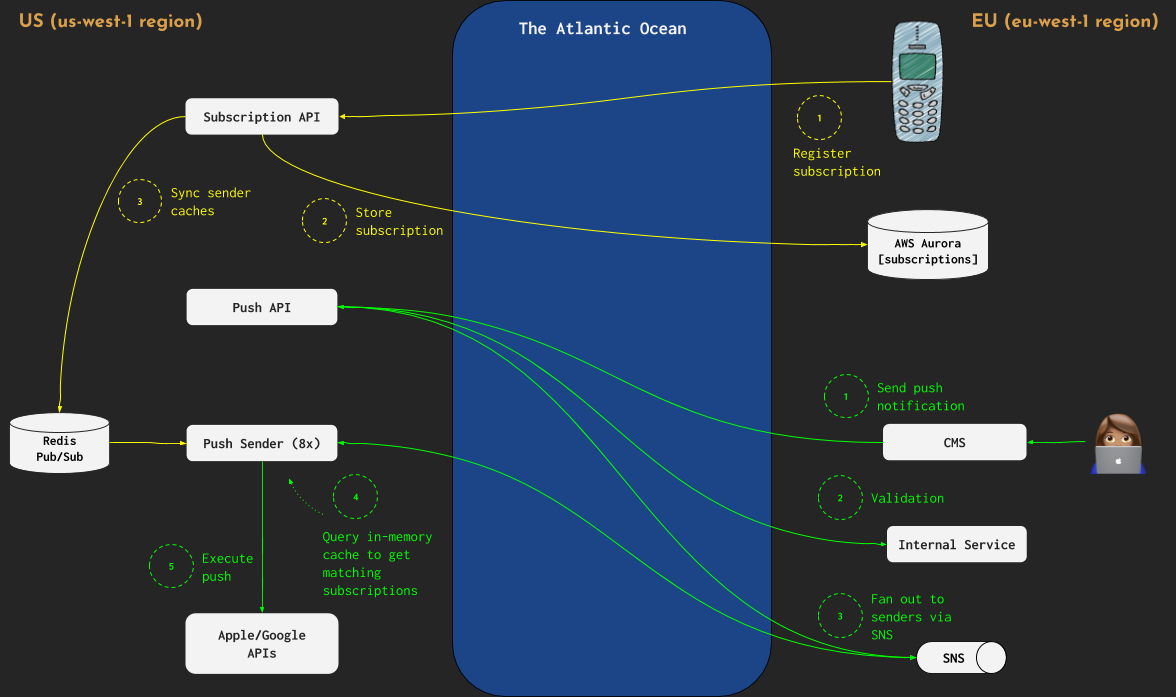
We realized that the way to go would be to “split” the Push Service and move some of its processes (subscription API, push API) back to Europe. Also, we redesigned the subscription API to put a user subscription on a queue (AWS SQS) and respond to the mobile device immediately. We introduced a new process called subscriptions worker (flow in orange) to read subscriptions in batches from the queue and then bulk insert to the permanent storage (AWS Aurora). We left the Redis instance responsible for the Pub/Sub in the US, but when sending cache sync notifications we switched to Redis pipelining and pushed those much faster.
To keep things simple the Push service was still one application kept in a single code repository. It was just deployed to two AWS regions. We scaled down to zero the processes that were not needed in a particular region.
The following diagram shows how it looked after the redesign:
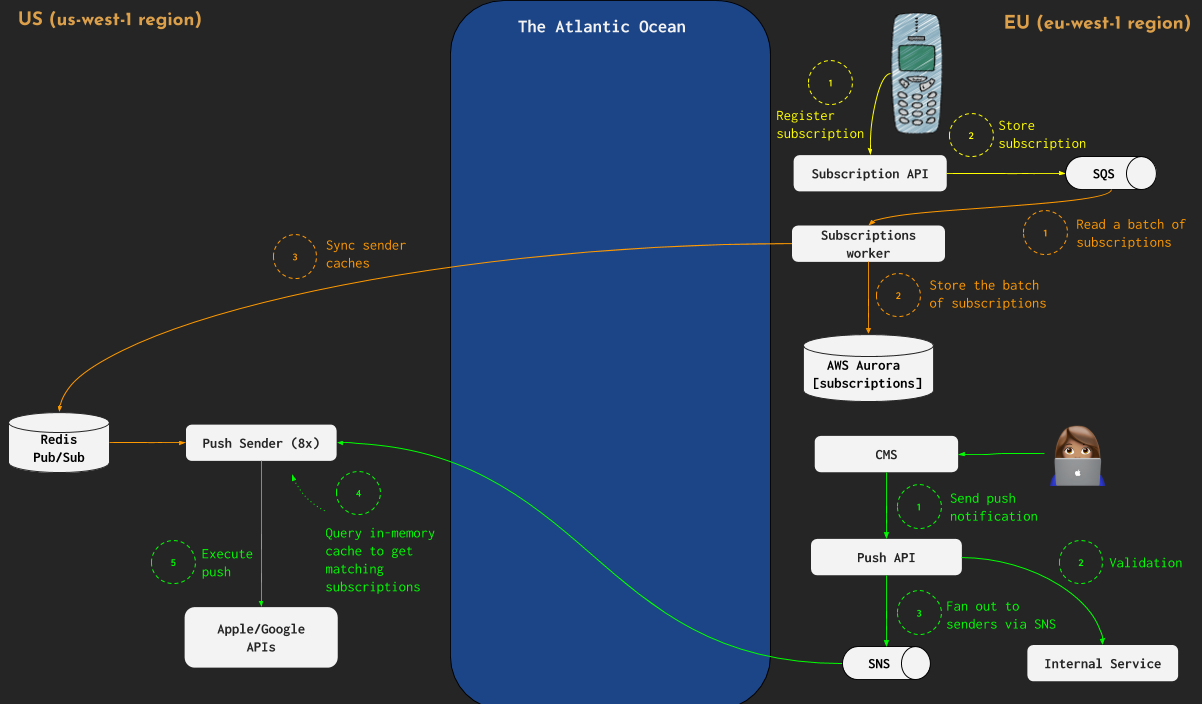
The solution above worked relatively well, meeting the performance requirements most of the time. To be honest, for some time we were fighting with memory leaks that, long story short, was caused by the pushy lib (fixed in version 0.13.11).
Optimization – drop Redis
In March 2020 AWS released Amazon Aurora Global Database for PostgreSQL. AWS promised to replicate data to a Postgres replica in another region with a typical replica lag of less than one second. We quickly realized that we could use this enhancement to further simplify our setup. For the Aurora instance we have in the EU we decided to deploy a replica in the US. Having Aurora close to senders we dropped the sender in-memory cache and instead queried the new US Aurora replica directly. This allowed us to drop Redis that we used to keep the caches in sync.
The following diagram shows how it looked after those changes:

It was pretty clear this would increase the push execution time. For each sender, it takes much more time to query its 30 shards in Postgres and scroll the results than to do the same against an in-memory cache. The total time to execute a push went up from 5-10 seconds to 15-20 seconds. It was temporarily acceptable as we already had a plan to further optimize the process and bring the execution time back down.
Optimization – flexible senders
To best visualize this optimization we will switch back to the architecture diagram we used earlier, without the region split. Let’s just update it with all the optimizations and changes we did so far.
The following diagram shows where we are:

Until now, we had static senders. It means that each of the senders had its limited view of the world consisting of 30 shards it was responsible for. This setup had major drawbacks. First, it was kind of hard to manipulate the number of senders. For each sender, the shards ranges were hardcoded, so tweaking the number of senders required manual shard adjustment for each. Also, we had to provision infrastructure (SQS) for every new sender. Lastly, the deployment process of any changes in this static setup was a bit complex.
We’d like to have a setup where we can change the number of the senders and thus throughput dynamically. This would allow us to scale them down during the night when news consumers sleep and in general, we do not send out push notifications. Also, we’d love to easily scale them up when important things happen, and delivering breaking news fast really matters.
We concluded that we cannot have static shards bounded to senders. If we could make the senders shard agnostic and provide the shard ranges dynamically the setup would be much more flexible.
Until now, the push API sent a single push message to an SNS. The SNS did a fan out to all the subscribed sender queues effectively delivering the same message to every sender. Each sender owned a range of 30 static shards and queried subscriptions in that range.
To get rid of static shards we decided that the push API would orchestrate the shards. It would send multiple messages to a single queue providing distinct shard ranges in the message metadata. The number of messages depends on the number of shards attached to each. Having 240 shards in total, if we eg. decide to attach 6 shards to each message then we need to send 40 messages to cover all the shards. So, a message from the push API to senders looks something like this:
Message payload:
{
"id": <UUID>,
"notification": <Nofitication data>,
..
}
SQS metadata:
{
"fromShard": 1,
"toShard": 6
}
On the other side of the SQS, we would have a bunch of senders picking up the messages from the single SQS concurrently. A sender would read shards from the message metadata and construct the query based on that.
The following diagram summarizes the changes:

Here is what we have gained. On the push API side, we can adjust the number of messages dynamically. We may decide to send eg. 60 messages with 4 shards attached to each, or 240 messages with 1 shard attached to each. On the senders side we can scale them up or down however we want since the senders do not hold any state. The more senders we have the faster we can consume the messages from the queue. Fewer shards per message mean fewer subscriptions to query and push to Apple/Google APIs for each sender process.
Currently, our push API sends 40 messages where each message points to 6 shards. On the other side of the SQS, we have 40 senders. In this setup our total push execution time when back down below 10 seconds.
Having no in-memory cache and fewer shards per sender allowed us to replace the expensive c5.xlarge EC2 instances with a larger number of cheap t3.small instances.
To wrap up I’d like to show a simple metric that we use to monitor the performance of the push operation. For every ordered push we mark on the following timeline the percentage of notifications delivered to mobile devices in:
- first 5 seconds (blue area)
- first 10 seconds (orange area)
- first 15 seconds (red area)

In November 2020 alone we delivered more than 2 billion push notifications to our users.
That’s it. Please leave a comment below, and let me know what you think!